Many great things have been said about using jemalloc, especially in the context
of memory-constrained environments, such as Heroku.
This is CodeTriage's Sidekiq worker memory use with and without jemalloc. I'm really starting to wonder how much of Ruby's memory problems are just caused by the allocator. pic.twitter.com/FD0fVbJCLt
— Nate Berkopec (@nateberkopec) December 1, 2017
What jemalloc is or how it works is outside the scope of this post (visit the
project’s homepage or read the
research paper
if you’d like to dive in).
What I’d like to show you is a specific case study of how jemalloc allowed me to double my
puma workers count on Heroku when I thought it wasn’t possible and how I did it.
The setup
Robin PRO is a pretty conventional Rails
app running on Heroku. With 512MB of memory at my disposal, I was originally running puma
with a single worker:
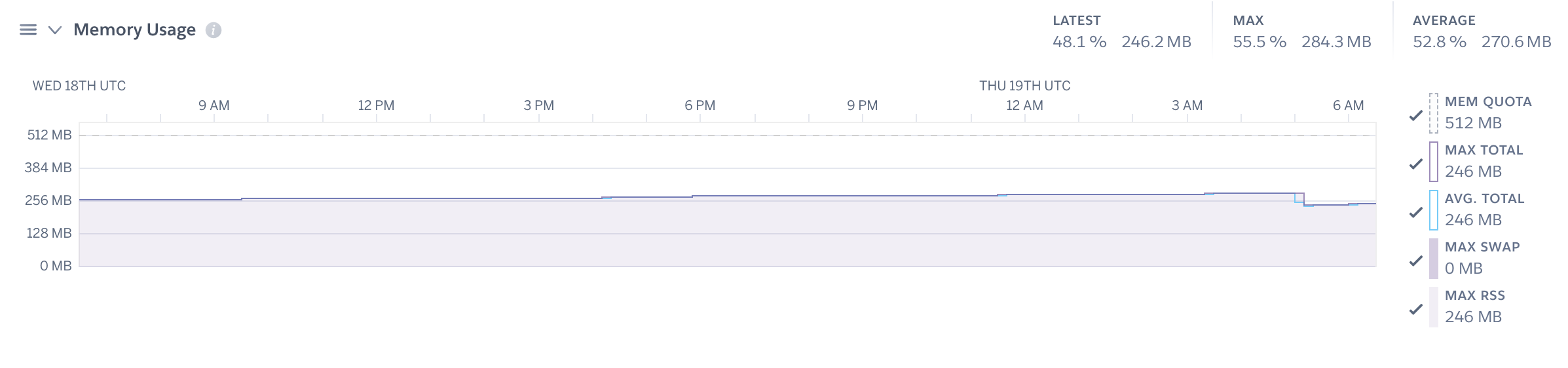
With so much memory available, it felt like I could just add one more web worker in order to optimize resource usage. Here’s the result:
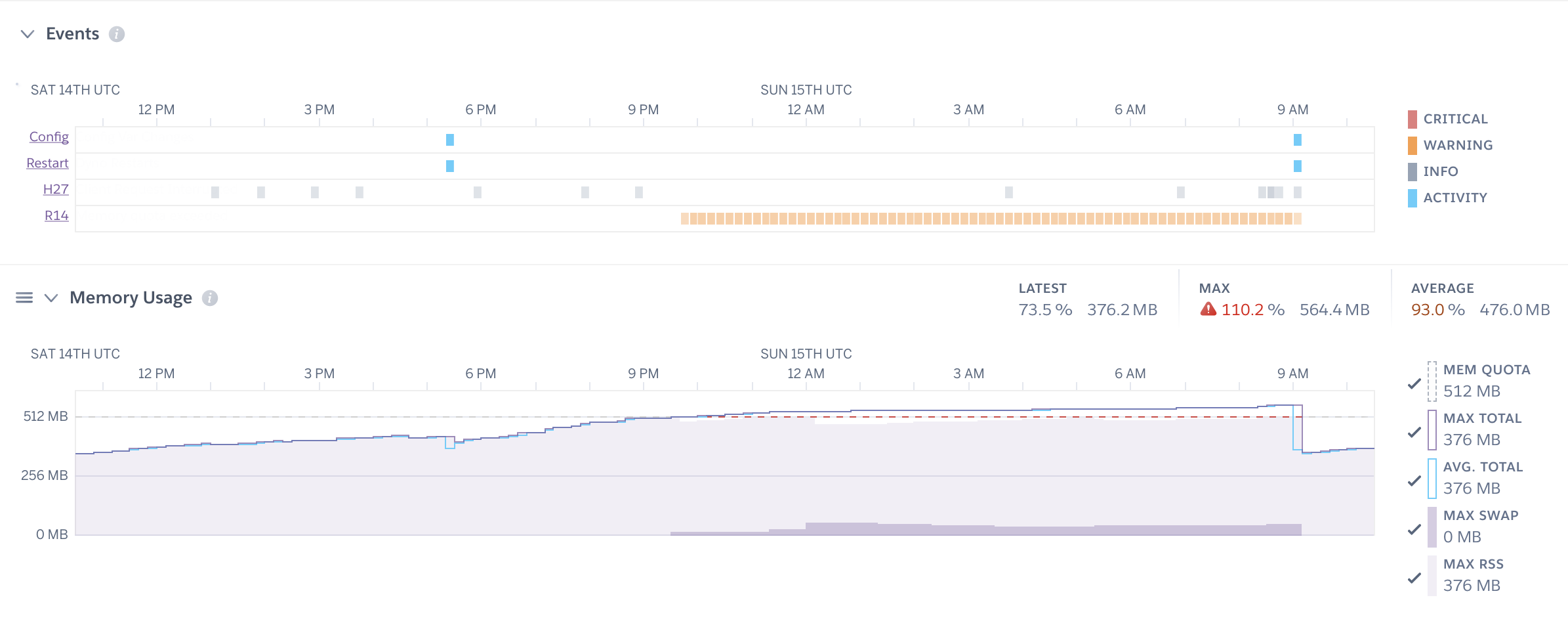
Conclusion: one web worker using ~50% of memory available but 2 going way over the allocated memory limit. This may look familiar to you.
Using jemalloc
Add the buildpack:
heroku buildpacks:add --index 1 https://github.com/gaffneyc/heroku-buildpack-jemalloc.git
Enable it for all dynos:
heroku config:set JEMALLOC_ENABLED=true
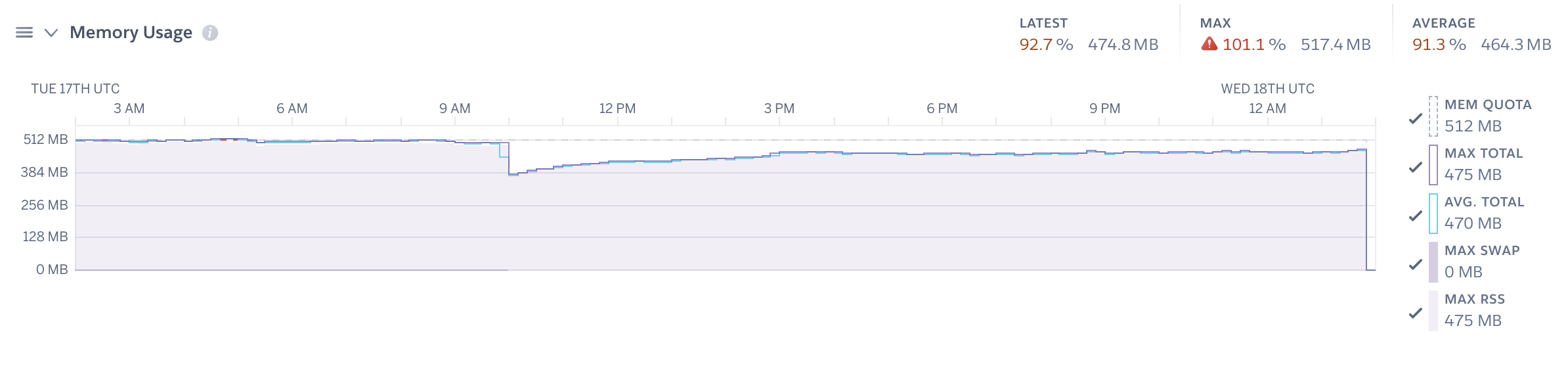
I have now been running it in production for two months and this is the most memory it’s ever used:
Caveats
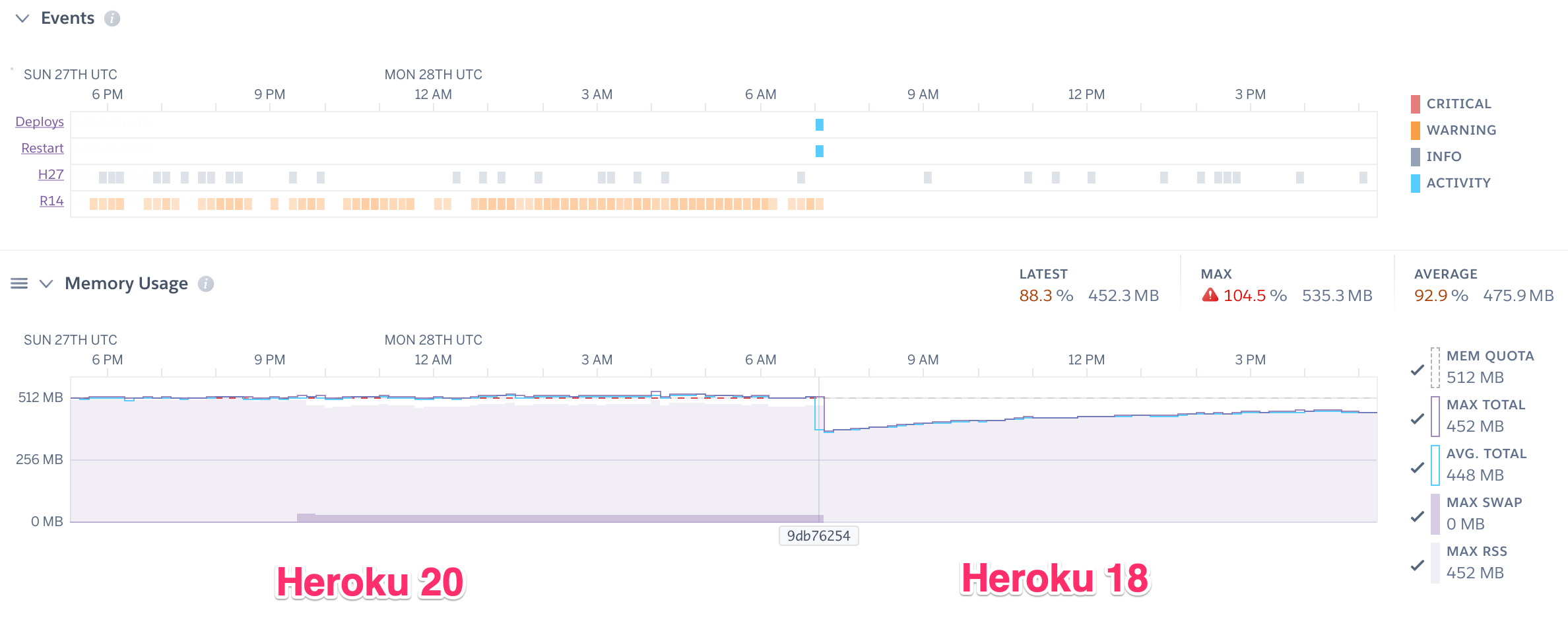
From my testing, this works equally well on heroku-16 and heroku-18 stacks. However,
memory usage seems to be consistently higher on heroku-20:
Why does it matter?
Being able to run 2 workers instead of a single one (especially when you’re starting out), thus doubling your app’s throughput absolutely for free is a major win.
Let’s take my specific scenario as an example.
Server costs: $7 (web dyno) + $7 (worker dyno) + $9 (Postgres) = $23/mo.
If I wanted to double my app’s throughput but couldn’t simply double my web worker count, I’d have to pay for one more web dyno. What’s worse, Heroku doesn’t allow you to to spin up multiple Hobby dynos, requiring you to upgrade to Standard 1X dynos. Here’s what the new equation looks like:
Server costs: 2 * $25 (web dynos) + $25 (worker dyno) + $9 (Postgres) = $84/mo.
That’s saving $61/mo for exactly the same outcome. Not bad!
Conclusion
I’m hoping this post inspires you to try increasing your app’s parallelism with jemalloc
even though you previously thought it wasn’t possible. There’s a very good chance you’ll
be able to increase your throughput or save some money. If you do, I’d love to read your
case study!